PCA for fault detection in Tennessee Eastman Process
In this notebook, the application of monitoring techniques is demonstrated, using data from the Tennessee Eastman Process benchmark.
import bibmon
import pandas as pd
import matplotlib.pyplot as plt
Process description
The Tennessee Eastman Process (TEP) is a realistic simulation of a process from Eastman Chemical Company, introduced as a benchmark for process control and monitoring applications (Downs and Vogel, 1993). The academic community has broadly embraced the TEP model for modeling studies, and it is now considered the most widely used benchmark for evaluating process monitoring techniques (MELO et al., 2022).
The TEP flowsheet is shown below. The objective of the process is to produce two products (G and H) from four reactants (A, C, D, and E), with the presence of an inert substance (B) and a by-product (F) within the process streams. The reactants A, C, D, and E, along with the inert B, are introduced into a stirred tank reactor, where the desired products G and H, as well as the by-product F, are generated. The resulting product stream then goes through a condenser followed by a vapor-liquid separator. Components that do not condense are recycled using a centrifugal compressor, while the condensate moves through a stripper, with the final products being collected from the bottom stream. Vapor is purged from the vapor-liquid separator to eliminate the inert substance and the by-product.
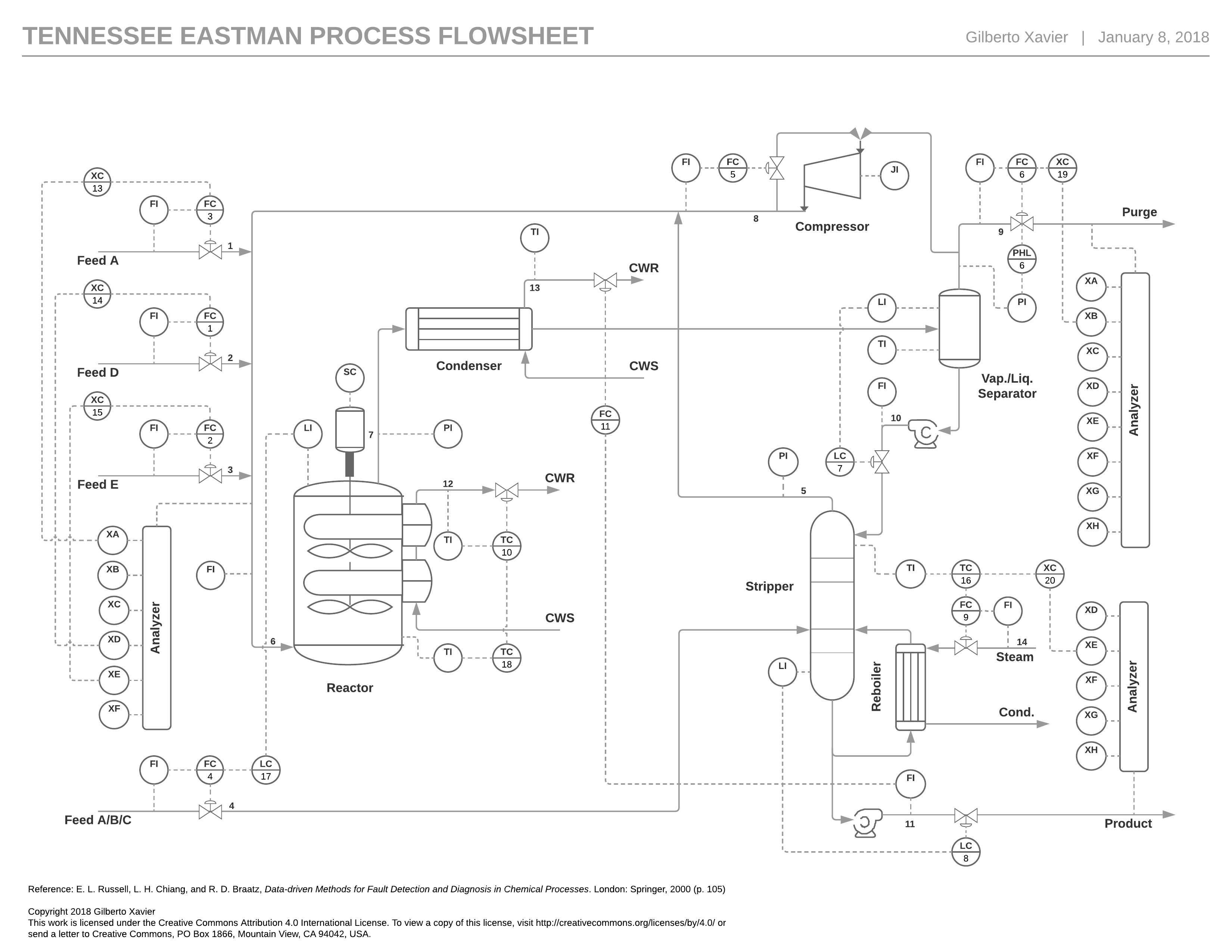
The original proposed simulation presumes the existence of 41 measured variables and 12 manipulated variables, with sampling intervals set at 3, 6, and 15 minutes. Below is a list of these variables.
Manipulated variables
Variable |
Description |
|---|---|
|
D Feed Flow (stream 2) (Corrected Order) |
|
E Feed Flow (stream 3) (Corrected Order) |
|
A Feed Flow (stream 1) (Corrected Order) |
|
A and C Feed Flow (stream 4) |
|
Compressor Recycle Valve |
|
Purge Valve (stream 9) |
|
Separator Pot Liquid Flow (stream 10) |
|
Stripper Liquid Product Flow (stream 11) |
|
Stripper Steam Valve |
|
Reactor Cooling Water Flow |
|
Condenser Cooling Water Flow |
|
Agitator Speed |
Continuous process measurement
Variable |
Description |
unit |
|---|---|---|
|
A Feed (stream 1) |
kscmh |
|
D Feed (stream 2) |
kg/hr |
|
E Feed (stream 3) |
kg/hr |
|
A and C Feed (stream 4) |
kscmh |
|
Recycle Flow (stream 8) |
kscmh |
|
Reactor Feed Rate (stream 6) |
kscmh |
|
Reactor Pressure |
kPa gauge |
|
Reactor Level |
% |
|
Reactor Temperature |
Deg C |
|
Purge Rate (stream 9) |
kscmh |
|
Product Sep Temp |
Deg C |
|
Product Sep Level |
% |
|
Prod Sep Pressure |
kPa gauge |
|
Prod Sep Underflow (stream 10) |
m3/hr |
|
Stripper Level |
% |
|
Stripper Pressure |
kPa gauge |
|
Stripper Underflow (stream 11) |
m3/hr |
|
Stripper Temperature |
Deg C |
|
Stripper Steam Flow |
kg/hr |
|
Compressor Work |
kW |
|
Reactor Cooling Water Outlet Temp |
Deg C |
|
Separator Cooling Water Outlet Temp |
Deg C |
Sampled process measurement
Reactor Feed Analysis (Stream 6)
Sampling Frequency = 0.1 hr
Dead Time = 0.1 hr
Mole %
Variable |
Description |
|---|---|
|
Component A |
|
Component B |
|
Component C |
|
Component D |
|
Component E |
|
Component F |
Purge Gas Analysis (Stream 9)
Sampling Frequency = 0.1 hr
Dead Time = 0.1 hr
Mole %
Variable |
Description |
|---|---|
|
Component A |
|
Component B |
|
Component C |
|
Component D |
|
Component E |
|
Component F |
|
Component G |
|
Component H |
Product Analysis (Stream 11)
Sampling Frequency = 0.25 hr
Dead Time = 0.25 hr
Mole %
Variable |
Description |
|---|---|
|
Component D |
|
Component E |
|
Component F |
|
Component G |
|
Component H |
Process faults
The simulation provides 21 pre-programmed disturbances, which include the introduction of step disturbances, modification of measurement variability, occurrence of valve sticking, drift in reaction kinetics and the presence of unknown disturbances. Below is a list of these disturbances.
Disturbance |
Description |
|---|---|
|
A/C Feed Ratio, B Composition Constant (Stream 4) Step |
|
B Composition, A/C Ratio Constant (Stream 4) Step |
|
D Feed Temperature (Stream 2) Step |
|
Reactor Cooling Water Inlet Temperature Step |
|
Condenser Cooling Water Inlet Temperature Step |
|
A Feed Loss (Stream 1) Step |
|
C Header Pressure Loss - Reduced Availability (Stream 4) Step |
|
A, B, C Feed Composition (Stream 4) Random Variation |
|
D Feed Temperature (Stream 2) Random Variation |
|
C Feed Temperature (Stream 4) Random Variation |
|
Reactor Cooling Water Inlet Temperature Random Variation |
|
Condenser Cooling Water Inlet Temperature Random Variation |
|
Reaction Kinetics Slow Drift |
|
Reactor Cooling Water Valve Sticking |
|
Condenser Cooling Water Valve Sticking |
|
Unknown |
|
Unknown |
|
Unknown |
|
Unknown |
|
Unknown |
Typically, when the TEP benchmark is used for process monitoring applications, the goal is to develop a method for real-time detection and diagnosis of these disturbances.
For more details on the TEP process, please refer to the following article: https://doi.org/10.1016/j.compchemeng.2022.107964.
Importing data
The TEP simulation data originally provided by Chiang et al. (2000) can be imported into the library using the load_tennessee_eastman function. This function requires an argument to specify the nature of data: use 0 for normal operation data and values from 1 to 20 for various process disturbances. Below, we demonstrate how to import normal operation data for training purposes and data corresponding to disturbance event IDV(1) for testing. In this dataset, disturbances are introduced after 8 hours of operation. By convention, normal datasets start on 2020-01-01 00:00:00 and faulty datasets start on 2020-02-01 00:00:00.
df_train, df_test = bibmon.load_tennessee_eastman(train_id = 0, test_id = 1)
fault_start = '2020-02-01 08:00:00'
Let’s visualize the datasets to gain insights into the types of behaviors we are modeling (normal data) and attempting to detect (faulty data):
def plot_tep_fault(df_train, df_test):
fig, ax = plt.subplots(22, 3, figsize=(15, 30))
for i in range(22):
ax[i,0].plot(df_train.iloc[:,i].values,c='k',linewidth=0.8)
ax[i,0].plot(df_test.iloc[:,i].values,c='r',linewidth=0.8)
ax[i,0].axvline(160, ls='--')
ax[i,0].set_yticks([])
ax[i,0].set_ylabel(i+1,rotation=0,fontsize=14)
for j in range(3):
ax[i,j].spines["top"].set_visible(False)
ax[i,j].spines["right"].set_visible(False)
ax[i,j].spines["left"].set_visible(False)
if i<(22-1):
ax[i,0].set_xticks([])
ax[i,0].spines["bottom"].set_visible(False)
for i in range(19):
ax[i,1].plot(df_train.iloc[:,i+22].values,c='k',linewidth=0.8)
ax[i,1].plot(df_test.iloc[:,i+22].values,c='r',linewidth=0.8)
ax[i,1].axvline(160, ls='--')
ax[i,1].set_yticks([])
ax[i,1].set_ylabel(i+23,rotation=0,fontsize=14)
if i!=(19-1):
ax[i,1].set_xticks([])
ax[i,1].spines["bottom"].set_visible(False)
for i in range(11):
ax[i,2].plot(df_train.iloc[:,i+41].values,c='k',linewidth=0.8)
ax[i,2].plot(df_test.iloc[:,i+41].values,c='r',linewidth=0.8)
ax[i,2].axvline(160, ls='--')
ax[i,2].set_yticks([])
ax[i,2].set_ylabel(i+42,rotation=0,fontsize=14)
if i!=(11-1):
ax[i,2].set_xticks([])
ax[i,2].spines["bottom"].set_visible(False)
for i in range(19,22):
ax[i,1].axis('off')
for i in range(11,22):
ax[i,2].axis('off')
ax[0,0].set_title('Continuous process variables',fontsize=14)
ax[0,1].set_title('Sampled composition variables',fontsize=14)
ax[0,2].set_title('Continuous manipulated variables',fontsize=14);
plot_tep_fault(df_train, df_test)
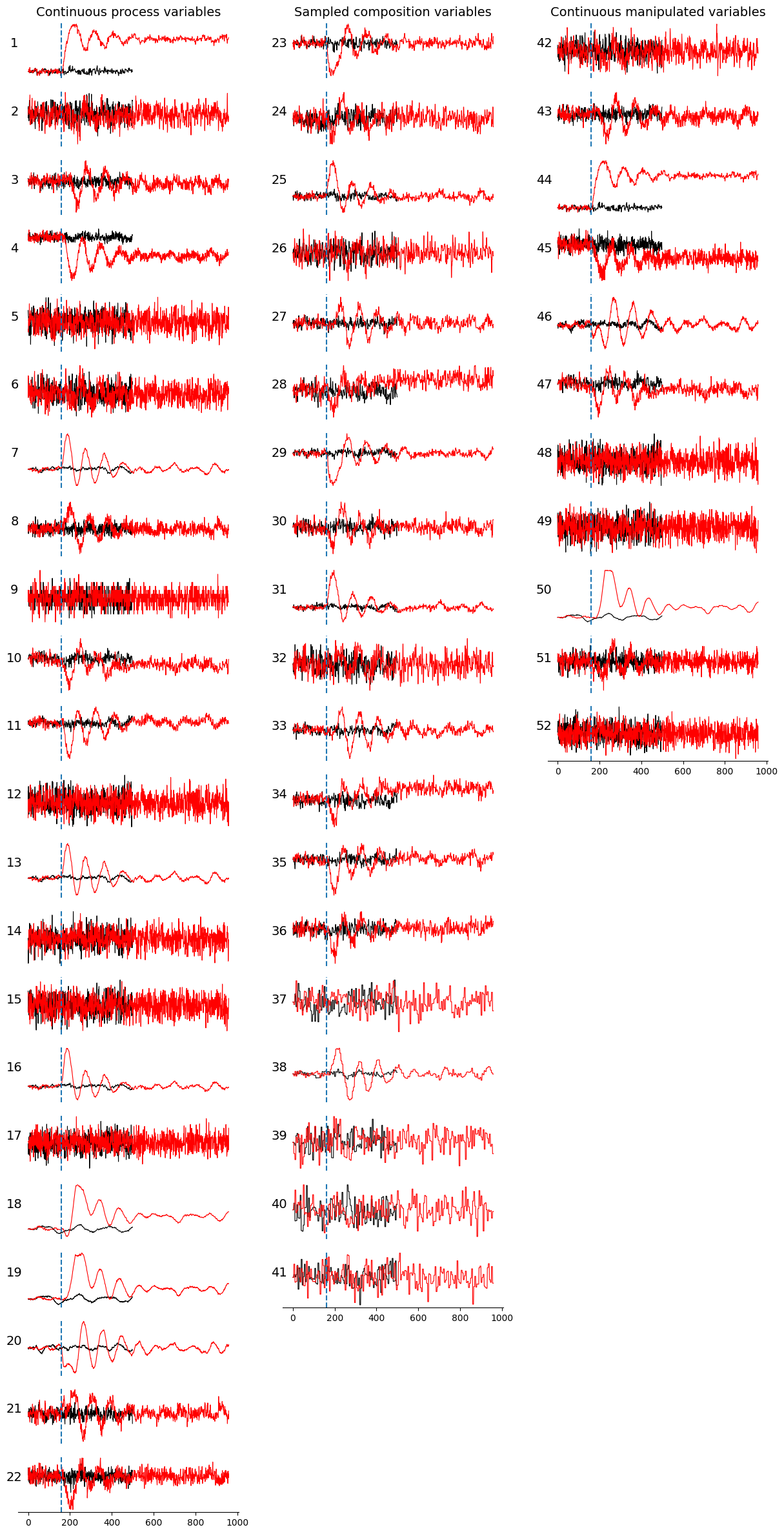
In the plot above, normal data is represented by black lines, while faulty data is indicated by red lines. The onset of the event, marked by a step change in the A/C feed ratio, is shown as a vertical blue dashed line. Observe that following the onset of the event, the variable values deviate from their normal ranges, exhibit an oscillatory pattern due to the automatic process control loop, and eventually stabilize. For some variables, stabilization occurs within the same range, whereas for others, it occurs in different ranges.
Modeling and process monitoring
The PCA model
The model discussed in this tutorial is Principal Component Analysis (PCA), a widely used technique in fault detection and diagnosis for process systems engineering applications. PCA generates a set of orthogonal linear combinations of the original variables, aiming to select a subset of these combinations that effectively captures and summarizes the data’s variability. It achieves this by ordering the principal components based on the amount of variability they explain. The first principal component represents the direction with the greatest data variation, while the second principal component is orthogonal to the first, and this pattern continues for subsequent components. A subset of these principal components is then chosen to adequately summarize the data’s variability, a process known as dimensionality reduction.
The following figure illustrates this procedure using a bidimensional example dataset. In the first plot, the red arrows represent the two principal components, with the larger arrow indicating the first principal component, which is associated with the direction of higher data variability. The second plot demonstrates the linear transformation applied by PCA, which is simply a rotation to position the first principal component in the direction of the x-axis. The third plot shows the dimensionality reduction step, where the bidimensional data is transformed into a unidimensional representation, eliminating the second dimension. Finally, the last plot depicts the reconstruction process, in which the data is projected back into the original bidimensional space, but now with variation only along the direction of the first principal component.
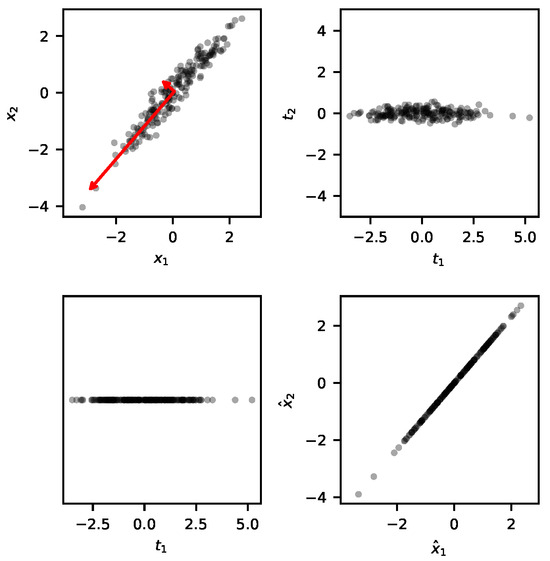
When PCA is applied to fault detection, the principal components are selected using the training data. These principal components are expected to explain the variability of the test data as well. If the test data’s variability is not adequately explained by the principal components identified during training, the process is considered to be faulty and alarms are trigged.
For more details on the PCA model, please refer to the following article: https://doi.org/10.3390/pr12020251.
Training the model
The following command instantiates a BibMon’s PCA model:
model = bibmon.PCA()
To train the model, we use the fit method:
model.fit(df_train)
The fault detection index used by BibMon is the Squared Prediction Error (SPE). This index is based on the difference between the measured data, \(\mathbf{X}\), and the data reconstructed by the model, \(\mathbf{\hat{X}}\):
The higher the SPE values, the greater the likelihood that the captured PCA model does not adequately explain the variability in the data, indicating that the process is not in its normal state.
Let’s create a control chart of SPE values for the training data:
model.plot_SPE(train_or_test = 'train')
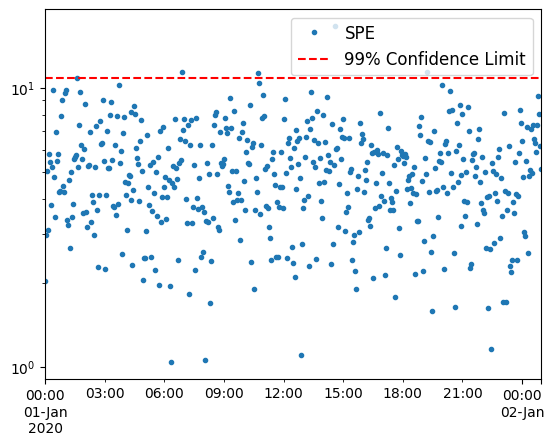
The confidence limit is established to ensure that 99% of the training SPE points fall below it. If new data points exceed this limit, it indicates a deviation from normal operation, triggering alarms.
Overfitting to the training data often leads to an underestimation of the confidence limit. To mitigate this, we can reserve a portion of the data at the end of the time series exclusively for setting the limit, rather than using it for training. This practice generally raises the limit and reduces false alarm rates. To implement this, we set the redefine_limit parameter to True, and the fraction of data reserved is specified by the frac_val parameter:
model.fit(df_train, redefine_limit = True, frac_val = 0.1)
Another useful visualization is the explained variance identified by the model:
model.plot_cumulative_variance()
plt.gca().axvline(model.n,ls='--');
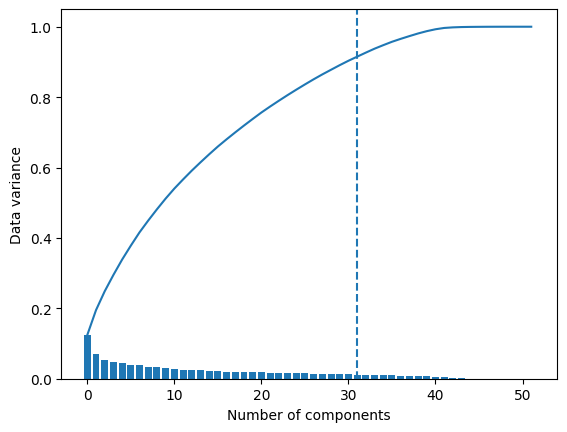
In the above plot, bars represent the data variance captured by each component, while the continuous line shows the cumulative variance. The vertical dashed line indicates the number of principal components retained by the model. By default, this number is set to ensure that these components together account for 90% of the variability in the data.
Applying the model to test data
To apply the model to a test dataset, we use the function predict:
model.predict(df_test)
Let’s plot the SPE chart for the test:
model.plot_SPE(train_or_test = 'test')
plt.gca().axvline(fault_start);
plt.title(f'FDR: {model.alarmOutlier[fault_start:].mean()}');
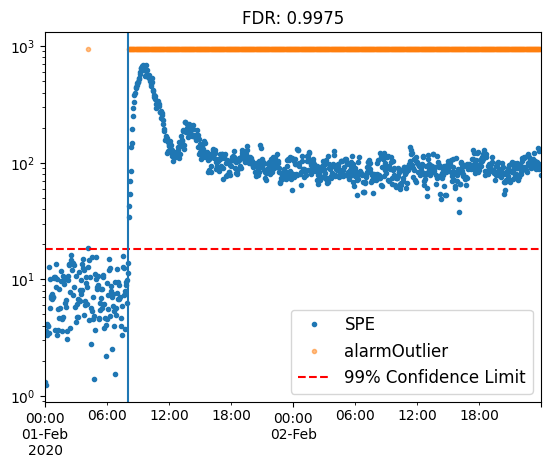
Observe how the SPE points rapidly increase as the faulty event begins, surpassing the confidence limit and triggering alarms, which are represented by the orange points. The fault detection rate (FDR) exceeds 99%, demonstrating the high capability of PCA in detecting this type of fault.
Now let’s plot the SPE contribution heatmap for the test:
model.SPE_contrib_test
| XMEAS(1) | XMEAS(2) | XMEAS(3) | XMEAS(4) | XMEAS(5) | XMEAS(6) | XMEAS(7) | XMEAS(8) | XMEAS(9) | XMEAS(10) | ... | XMV(2) | XMV(3) | XMV(4) | XMV(5) | XMV(6) | XMV(7) | XMV(8) | XMV(9) | XMV(10) | XMV(11) | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 2020-02-01 00:00:00 | 0.001014 | 0.064975 | 0.037878 | 0.246770 | 0.181036 | 0.004409 | 0.033778 | 0.009796 | 0.304754 | 0.004927 | ... | 0.059832 | 0.002372 | 0.103276 | 0.008692 | 0.000253 | 0.099966 | 0.037930 | 0.011821 | 0.309943 | 0.002010 |
| 2020-02-01 00:03:00 | 0.002600 | 0.003200 | 0.017056 | 0.005200 | 0.075389 | 0.537488 | 0.047553 | 0.004073 | 0.161714 | 0.000592 | ... | 0.107089 | 0.000121 | 0.002754 | 0.034813 | 0.002286 | 0.010254 | 0.036163 | 0.015417 | 0.051729 | 0.000530 |
| 2020-02-01 00:06:00 | 0.003463 | 0.335738 | 0.087237 | 0.448906 | 0.082531 | 0.034783 | 0.034252 | 0.036815 | 0.604998 | 0.028912 | ... | 0.095856 | 0.003716 | 0.084730 | 0.006780 | 0.002523 | 0.019461 | 0.011476 | 0.042128 | 0.103812 | 0.010718 |
| 2020-02-01 00:09:00 | 0.005135 | 0.050067 | 0.336866 | 0.083280 | 0.025785 | 0.022209 | 0.000098 | 0.043427 | 0.198501 | 0.016713 | ... | 0.466475 | 0.003634 | 0.702181 | 0.000092 | 0.010344 | 0.024591 | 0.007360 | 0.013008 | 0.068126 | 0.010793 |
| 2020-02-01 00:12:00 | 0.106140 | 0.387329 | 0.008186 | 2.278590 | 0.096295 | 0.041390 | 0.088964 | 0.080601 | 0.366359 | 0.069751 | ... | 0.101740 | 0.196166 | 1.729925 | 0.007866 | 0.020661 | 0.014950 | 0.009739 | 0.007056 | 0.216235 | 0.010852 |
| ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... | ... |
| 2020-02-02 23:45:00 | 30.408410 | 0.031451 | 0.503471 | 22.163046 | 1.072180 | 0.001327 | 0.122422 | 0.840029 | 0.108932 | 2.289084 | ... | 0.184355 | 29.940564 | 9.990535 | 0.148251 | 1.219644 | 0.031778 | 0.040662 | 2.282846 | 0.068765 | 0.359752 |
| 2020-02-02 23:48:00 | 31.467704 | 0.272619 | 0.911882 | 11.481591 | 0.603022 | 0.027659 | 0.382506 | 0.029068 | 0.024013 | 2.581854 | ... | 0.276890 | 31.187571 | 3.705808 | 0.848143 | 0.961667 | 0.016849 | 0.144884 | 2.416294 | 1.281990 | 0.273778 |
| 2020-02-02 23:51:00 | 30.315880 | 0.455588 | 0.153864 | 15.412005 | 0.317337 | 0.211359 | 0.150044 | 0.168905 | 0.011646 | 2.625218 | ... | 0.025977 | 30.445067 | 6.954743 | 3.053719 | 0.848270 | 0.130417 | 0.349548 | 2.305401 | 0.106318 | 0.106629 |
| 2020-02-02 23:54:00 | 31.400179 | 0.331269 | 0.090643 | 7.593507 | 1.265269 | 0.034129 | 0.064121 | 0.157971 | 0.144850 | 0.235651 | ... | 0.150828 | 31.839818 | 3.874597 | 0.507650 | 0.034667 | 0.384894 | 0.086569 | 1.222012 | 0.090505 | 0.322083 |
| 2020-02-02 23:57:00 | 33.666126 | 0.362147 | 0.431882 | 10.233358 | 1.200758 | 0.146887 | 0.000917 | 0.036429 | 0.143768 | 0.039342 | ... | 0.015368 | 32.429301 | 4.799023 | 0.922214 | 0.262240 | 0.009751 | 0.056689 | 0.646388 | 0.132035 | 0.550161 |
960 rows × 52 columns
model.plot_SPE_contributions()
plt.gca().axhline(y=model.X_test.index.get_loc(fault_start),ls='--',c='r');
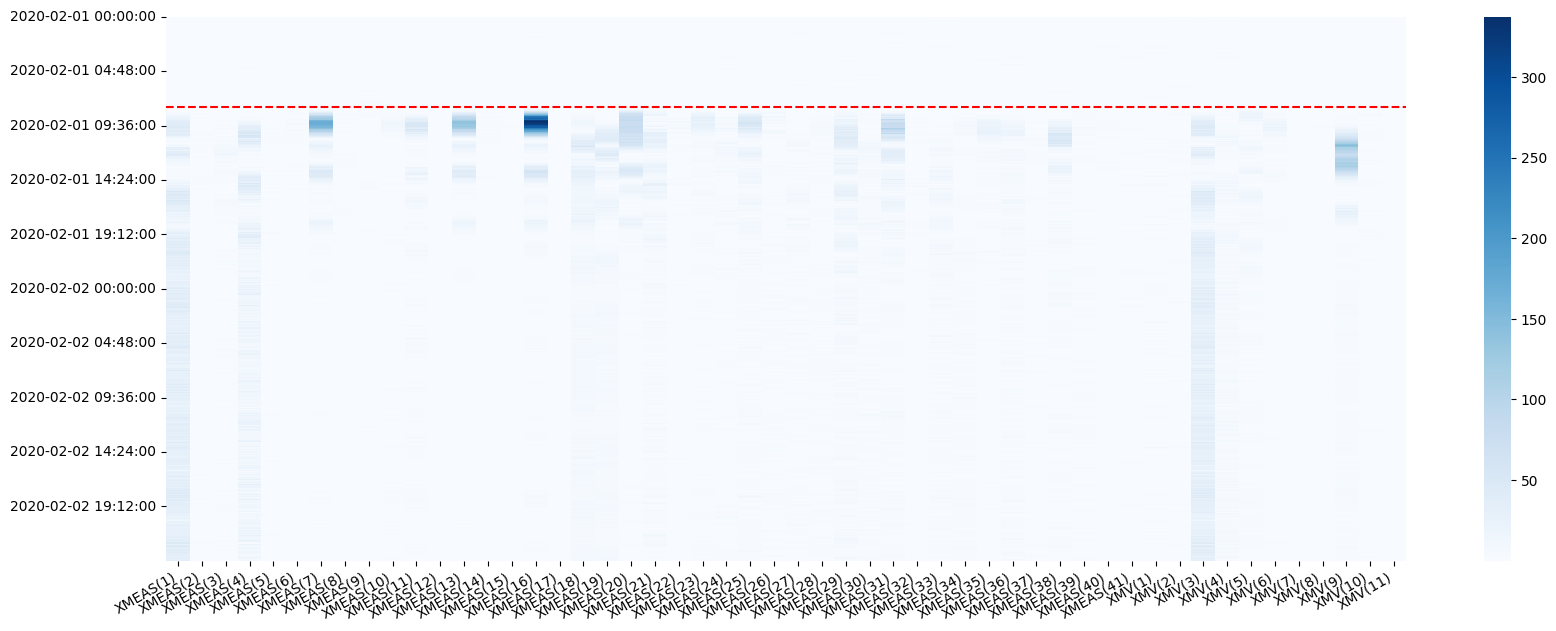
This map illustrates the contribution of each variable, at every time step, to the squared prediction error. It provides insights into the relative connection of each variable to the event, whether as a causal factor or a consequential outcome. Compare this plot with the time series visualization we examined earlier!
Analyzing the effect of preprocessing techniques
In BibMon, applying preprocessing techniques is straightforward: simply define lists with the names of the functions in the desired order of application, and provide them to the fit and predict methods.
In the TEP process, specifically in the IDV-11 case, the fault detection rate improves with the application of noise filtering techniques and the addition of dynamics through lags.
df_train, df_test = bibmon.load_tennessee_eastman(train_id = 0, test_id = 11)
Using the default pre-processing pipeline
The default preprocessing pipeline is as follows:
training:
['remove_empty_variables', 'ffill_nan', 'remove_frozen_variables', 'normalize'];test:
['replace_nan_with_values', 'normalize'].
model = bibmon.PCA()
model.fit(df_train, redefine_limit = True, frac_val = 0.1)
model.predict(df_test)
model.plot_SPE(train_or_test = 'test')
plt.gca().axvline(fault_start);
plt.title(f'FDR: {model.alarmOutlier[fault_start:].mean()}');
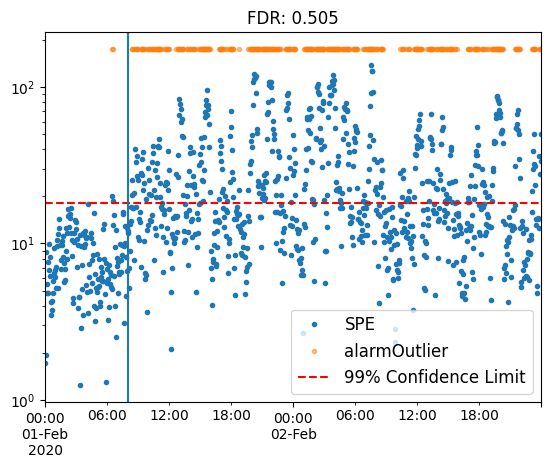
Applying lag
model = bibmon.PCA()
preproc = ['apply_lag', 'normalize']
model.fit(df_train, f_pp = preproc, f_pp_test = preproc, redefine_limit = True, frac_val = 0.1)
model.predict(df_test)
model.plot_SPE(train_or_test = 'test')
plt.gca().axvline(fault_start);
plt.title(f'FDR: {model.alarmOutlier[fault_start:].mean()}');
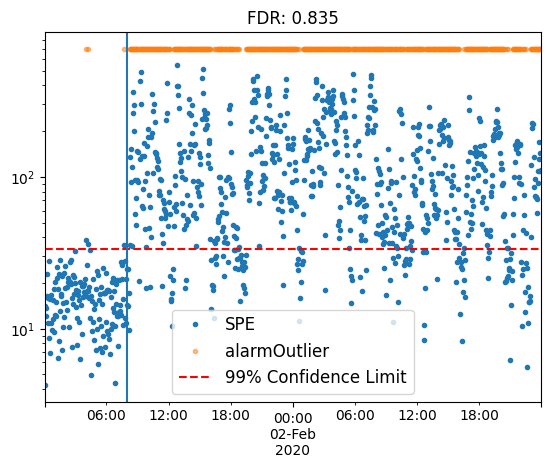
Notice how the normalize method was added to the pipeline, as it is essential prior to applying PCA modeling.
Applying a moving average filter
model = bibmon.PCA()
preproc = ['moving_average_filter', 'normalize']
model.fit(df_train, f_pp = preproc, f_pp_test = preproc, redefine_limit = True, frac_val = 0.1)
model.predict(df_test)
model.plot_SPE(train_or_test = 'test')
plt.gca().axvline(fault_start);
plt.title(f'FDR: {model.alarmOutlier[fault_start:].mean()}');
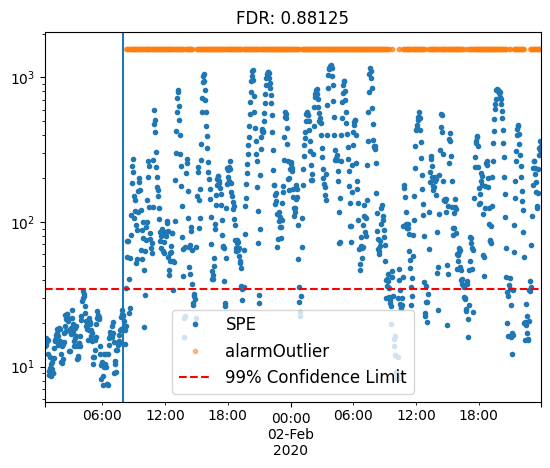
Applying filter and lag, modifying parameters using the args_preproc argument
model = bibmon.PCA()
preproc = ['apply_lag', 'moving_average_filter', 'normalize']
args_preproc = {'moving_average_filter__WS': 5, 'apply_lag__lag': 5}
model.fit(df_train, f_pp = preproc, a_pp = args_preproc,
f_pp_test = preproc, a_pp_test = args_preproc,
redefine_limit = True, frac_val = 0.1)
model.predict(df_test)
model.plot_SPE(train_or_test = 'test')
plt.gca().axvline(fault_start);
plt.title(f'FDR: {model.alarmOutlier[fault_start:].mean()}');
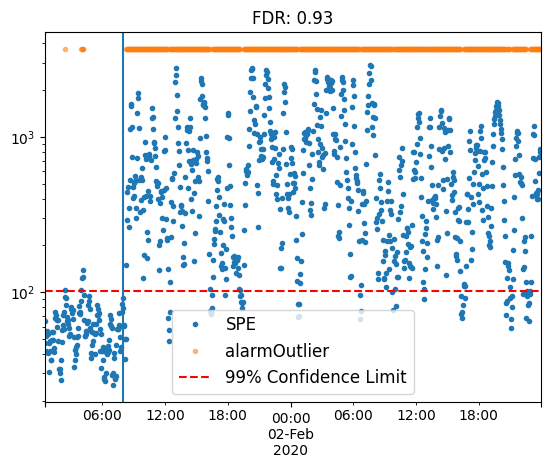
By employing various preprocessing techniques, we can boost fault detection rates from a baseline of 50.5% to 93%.
Final considerations
This notebook provides an example of an offline monitoring study utilizing the PCA model.
For a demonstration of BibMon’s high-level functions, which allow for the rapid execution of a complete process monitoring pipeline for analysis and methodology comparison, please refer to the tutorial_real_process.ipynb notebook.